In 2013 I decided to turn jobs. I was a teacher in Special Needs education and wanted to become a front-end developer. When you’re a front-end starter, it is important to know the basics of the web. There are a lot of topics on front-end development that can be found on the Internet. Most topics that starters are learning are HTML, CSS and JavaScript or jQuery. These are topics that will be learned by doing. Are these the real basics of front-end development? In a way yes, but one of the real basics is HTTP. I explored the web to find good references to read and learn about this topic. Well there is enough to find but not that much about this topic. Is it not important or is it not sexy to write about this topic? Don’t know, but this article is for web dev starters to show them the basics of HTTP.
What is HTTP?
Ludovico Fischer calls HTTP the life of the web. And as front-end developer it’s also your lives, you will earn our money with HTTP. What is this HTTP then? If we look at us humans, we can talk to each other. We put letters behind each other and those letters make words. We put these words in a certain order to make sentences. The order in which we put these words is based on rules. Because of these rules we know how to build sentences and with those we can build stories. These rules are important so we can understand each other better. If every one would make his or her own kind of sentences we still wouldn’t understand each other, even if we speak the same language. Some people wrote all of these rules down so everyone can use these rules. Now we can understand each other well. We have a lot of languages on our planet, but to make sure we can understand each other better, we humans said that English is the language of the world. So if we want to understand each other we better learn English. So we have rules how a language should be used and we said we have one language that we all can speak to understand each other, English. Computers need the same to understand each other. They also need rules about how they can communicate with each other and also one language to understand each other. For computers that are on the Internet there is one language they have to speak to understand each other and there are rules put in a protocol. This is where HTTP comes in. HTTP stands for Hypertext Transfer Protocol. As you can see it’s a protocol that describes how hypertext should be transferred. Nowadays it’s not only hypertext but also a lot of other media too, like images, sounds, movies, etc.
We have a language and this language has a protocol, HTTP. The transportation from HTTP goes from a client (for example a web browser) to a server, to another server, to a destination server and back to the client. This transportation goes with TCP and IP over wire, by air or satellite. It starts with a client who makes contact with a server; let’s say to wake the server. Then sends a request to a server for information and the server tries to reply with the information needed. They understand each other. Even though they are different brands, with different kind of software they all speak the same language, the HTTP language. If we hadn’t this, the Internet would not be useful. As you can see we speak of a request and trying when client and server are talking to each other. It is a request from the client to the server in which the client asks, “please try to match this”. The server will look and see what matches or comes closest and send the information that is the best match. It isn’t always possible to send the information that is requested. When a client requests for information in the Dutch language, but there is nothing in the Dutch language it will send what comes closest. In short, this is what HTTP is about. We will dive deeper into this subject in this next section. And talk about some parts of HTTP.
The different HTTP parts
HTTP has a header with Meta data and a body. The important part of the HTTP file is the header. The client sends information in the request-header to the server, like which client it is, if caching is possible, if there is a cookie for this website, if gzip is accepted by the client.
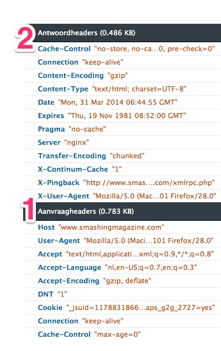
The server looks up which information is given to the server and tries to deliver the information that is asked for or tries to be as close by as possible. That means if gzipping is on it wil gzip the files. And the server gives the information (or data) that is asked for. It puts this in de body of the HTTP response and of it goes to the client. Together with the information that is send in de body, the server sends a response-header with information see number 2 in the image). This information is what you call meta-data. It is information about the data. This meta-data is in de header of the HTTP response and gives the client information, like the kind of server it is coming from, the kind of content it has in de body (text, html or an image), etc. The meta-data is not important for visitors of websites or people using web applications. They don’t see or hear it. For the client, the server and all the web developers it is important.
Good to now about HTTP
HTTP has more to offer then what this article covers. This article is about the basics of HTTP. When you want to know more about this subject read the links that are at the end of the article. Here is some basic and important knowledge of HTTP.
Verbs
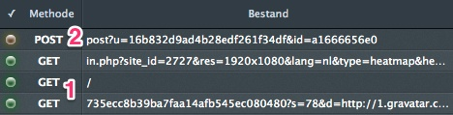
HTTP uses some verbs. These verbs are doing an action. Some of the verbs that are used in HTTP are GET, POST, PUT, DELETE. The most used verbs are GET and POST. GET number 1 in the image is used to get data from a webserver, like the HTML and the CSS. GET is used to build the website in a browser. GET is seen as a safe way of communication to a server, because it only wants to pick something up and deliver it to the client. POST number 2 in the image is used to bring new information to the server. A form on a website or a basket in a webshop are methods that use POST. In the image above is a Newsletter subscription used. This action uses POST to send this information to the server. POST is seen as an unsafe way of communication because it wants to change something on the server. When POST is done there should always be a redirect to another source. Because when you refresh and the information that was sent to the server will be sent twice. That’s not what the visitor wanted.
Status codes
When the client is contacting the server. The server will interpret the message of the client and talks back. It always gives back a status code. With this status code the client knows if the request was successful or not and what went wrong. The most known status code is the 404. This means that the client did do something wrong. Most of the time visitors of a website typed a wrong url. These are the status codes there are:
- 1xx: Informational - Request received, continuing process.
- 2xx: Success - The action was successfully received, understood, and accepted.
- 3xx: Redirection - Further action must be taken in order to complete the request.
- 4xx: Client Error - The request contains bad syntax or cannot be fulfilled.
- 5xx: Server Error - The server failed to fulfill an apparently valid request.
This list is coming from the RFC2616 document of the IETF. Each hundred number has some more codes it can give back to the client. Like the 404 is one of the 4xx numbers. Or 304 is one of the 3xx numbers. With 304 the server tells the client that nothing has changed. The server knows this because the client did send in the HTTP header when it was the last time it visited that server. This means that the client can grab a local copy of the information, which is faster then downloading it again.
For now it is important that you know what a status code is and which general numbers there are and what they mean. In the image below you see a GET request and the server sees that it doesn’t have to send it again because it was not modified and still in the cache of the client.

Cookies
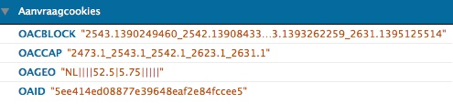
Cookies are sent with the http-header from the server to a client. With this cookie a server can see if a client has already been there. This means that when a client comes a second time on a server it will look for the cookie and send the cookie information with the HTTP header over to the server. The server now knows that the client already visited this server. See below how a cookie looks like. Not something that is eatable.
Caching
A browser stores data from websites like images, HTML, CSS, JS in a folder on the hard drive of a computer. This we call caching of the information. A client only does that when the server allows it. The server sends with the HTTP header information about caching from the data it is sending to the client. One of the things it sends is if caching is allowed, but also when the expire date of the cached material is and when the client has to look back on the server for new material.
Proxies
Because the HTTP information is based on text other machines can look at it and do something with it. Like a proxy. A proxy at an office can read the information that is sent through and for example throw it away. Because the proxy has to filter the requests that are going to twitter and facebook and don’t let them pass the proxy. The proxy can see in the HTTP header to which host a request is going.
Change the HTTP header
The HTTP request is changeable with jQuery. If you change the request of the client, the output of the server will also be different. See jQuery AJAX.
Webdeveloper tools
The best way of looking at HTTP is going to your web developer tools and look at the network tab. Here you find all the information needed. Take a look at the image below and read the explanation afterwards. What you see is the FireFox web developer tools. If you open the web developer tools go to Network and visit a website.
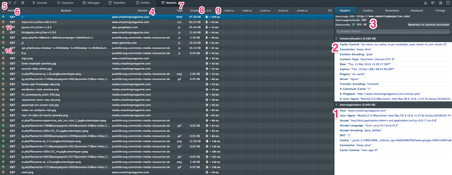
The request header (1) shows which website you visit, here it is Smashing Magazine. This is the header the web browser did send to the server of Smashing Magazine. The request header show the host the client wants to connect to, the user-agent, which is Mozilla FireFox, what it accepts, like language and kind of media, a cookie, etc. Above it is the response header (2) from the server of Smashing Magazine. We can see it is a nginx server, it had the data gzipped, and some more things. Above that (3) you can see the url that was requested, the client requested it with a GET method and the status code was 200, which means that it went OK. A lot of this information is also viewable at the left of the image. In the blue bar you see the url (4) that was requested, the status code (5) the server returned, the method was GET (6), the type of media it is (7), how big (8) it is and the time (9) it did cost to get to the client. There are many files that were coming to the client. They all did get in with a GET request. The media types are different, from JavaScript, to gif, png and html. The files are coming from different servers or from a subdomain. Look at the status code. There are two different kinds of status codes to see in this window. The green round one (10) and the orange round (11). The green one is a 200 OK, but the orange one is a 304. This means it is not modified since the last time the client visited Smashing Magazine. So these files could be retrieved from the local cache. There is a lot to see at the web developer tools about HTTP. It gives a lot more insight in what HTTP is. A good way to get around in HTTP and the web developer tools is reading about HTTP and watch at the same time in the web developer toolsbar.
Why should I know about it? What can I do with it?
This is the question we always have to ask our self when hearing about something. The same is with HTTP. Why should we know about this? Well when I was reading some articles about HTTP some pieces came together. HTTP gives more insight in how the web works. As a starter web dev you will know better how clients, like browsers, and servers work together and how they react on each other. Especially when you go more on the technical side of front-end development it is important to know this. You will become a better web apps and websites programmer. Because you know how the connection from a client to a server is best used and can take this in account for your web application. Understanding HTTP is important for debugging.
When I was a trainee at popaquestion.com we had to see how the server was responding on our POST and GET action with a form. We wanted a user become a member (POST) and that the questions this person made also would be linked to the username. So we had to look with the web developer tools how the server acted on our POST request and put the Username together with the id’s of the questions.
Knowing about HTTP can give you a better insight on performance of your website or application. When working on bigger projects the project team mostly has influence on the choice of webserver. Then the project team has to think about how HTTP influences the performance. By knowing HTTP you know which setup of the webserver will give the best performance for you website or application. Like checking the webserver its configuration and seeing if keepalive is enabled. This will save a lot of time. Now the client only has to make contact to the server once. Making contact is just a few milliseconds. But a website or application nowadays needs to do this around 90 times to get al the information that is needed to show the website or application. Keepalive takes care of this by keeping the connection open until all the information the client needs is send and the last package will have a connection close in the HTTP header. Or something like HTTP pipelining can be used in applications and reduces waiting time. It should be supported by the client and the server. Pipelining will send a request for the HTML and CSS at the same time, these GET requests will be processed by the server at the same time and will be send to the client after each other. This will safe some extra time.
The future
The IETF has a working group named HTTPbis who are working on HTTP 2.0. It will be mainly focused on performance. As they call it there self: “HTTP/2 enables a more efficient use of network resources and a reduced perception of latency by introducing header field compression and allowing multiple concurrent messages on the same connection.” But HTTP 2.0 will do more. It will know how to prioritize; it lets more important requests come first. Another thing that will be better is that less TCP connections will be needed. That will be possible because it will have parallel requests and responses in one connection. Also an interesting thing is the server push, which means that a server knows which information the client needs, so it will already send this information before it is needed. The future is looking interesting for HTTP. If you want to read more about this future and go in depth read, “HTTP continues to evolve” by Ilya Grigorik.
Resume
In this article are some basics of HTTP explained. If you want to learn more about HTTP go and read the recourses that were used for this article. The important things that were mentioned in this article are: HTTP lets clients and servers talk to and understand each other on the Internet. HTTP uses a header for sending meta data to a server and back to a client which helps the communications between them. HTTP uses some verbs, which are actions. Like GET, PUT, DELETE, POST, etc. GET and POST are the most used ones. With GET data is coming from the server. With POST data will be changed or put on the server. Like an username on a description form. A server sends a status code to the client, so the client knows how the communication went. HTTP helps with the caching of data on the local machine with information that is stored in the header of the HTTP request and response. We started with HTTP 0.9. Now the web is many years on HTTP 1.1, but we see the end of this. HTTP 2.0 is coming closer to the web, which means the web will be faster. Yes! But other protocols are still there and could be a bottleneck. Like TCP or IP. And according to Ilya latency is also still a problem and costs some extra time.
“We are in a great industry, an industry of movement”.
Recources
- The best place to start is the free book of Ilya Grigorik “High Performance Networking”.
- http://code.tutsplus.com/series/http-succinctly--net-33683
- http://code.tutsplus.com/tutorials/http-the-protocol-every-web-developer-must-know-part-1--net-31177
- http://code.tutsplus.com/tutorials/http-the-protocol-every-web-developer-must-know-part-2--net-31155
- http://www.ietf.org/rfc/rfc2616.txt and http://www.w3.org/Protocols/rfc2616/rfc2616.html
- https://datatracker.ietf.org/doc/draft-ietf-httpbis-http2/?include_text=1
- http://tools.ietf.org/html/draft-ietf-httpbis-http2-10